
In vielen Büros und auch einigen Uni-Bibliotheken stehen ja inzwischen Einzugsscanner, mit denen man umfangreichere Skripte ohne großen Zeitaufwand einscannen kann. Das eingelesene PDF-Dokument wird einem dann per E-Mail zugeschickt. Eigentlich geht das recht leicht, aber allzu leicht geht dabei auch mal etwas schief. Die Seiten sind verdreht, oder der Scanner meinte eine A3-Seite zu erkennen, obwohl man eigentlich nur Dokument im A4-Modus einscannen wollte. Man könnte sich natürlich wieder sein Skript packen und das Ganze neu einscannen, man kann das PDF aber auch zuschneiden und aufräumen. Mit PDFcrop, Briss, PDF-Quench und PDFShuffler gibt es dazu vier wunderbare Tools.
Liebe Ubuntu-User, auch wenn ich in meinen Beiträgen nach wie vor Informationen zu Ubuntu und Debian einbinde, bin ich aktuell vorwiegend unter Arch Linux zuhause. Beachtet daher, dass ich meine Beiträge daher primär auf Arch und die aus den Arch-Repositories installierbare Software beziehe. Ich versuche aber meine Beiträge so „ubuntuig“ wie möglich zu halten und teste wichtige Details in virtuellen Maschinen aus.
Automatisch zuschneiden mit PDFCrop
Das erste Tool, das ich euch in dieser Reihe vorstellen möchte ist PDFCrop. Das kleine Perl-Skript schnappt sich ein PDF und schnippelt automatisch Seite für Seite das weg, was nicht hingehört und zieht den Rest auf eine Standard-Papiergröße hoch. Aus meiner Erfahrung heraus arbeitet PDFCrop aber nur dann richtig gut, wenn das PDF viel Whitespace enthält. Wurde beim Scannen viel Dreck und Rauschen im Whitespace eingebaut, dann kommt PDFCrop leider schnell aus dem Tritt. Für einen ersten Durchlauf bietet sich die Anwendung aber in meinen Augen sehr gut an, vor allen Dingen weil alles automatisch abläuft.
PDFCrop kann man unter Debian/Ubuntu wohl leider nicht mehr aus den Paketquellen installieren — zu Zeiten von Ubuntu Gutsy war es wohl mal enthalten. Aktuell spucken beide Distributionen bei der Suche nach dem Programm nichts aus. Allerdings lässt sich das Skript auch von Hand sehr einfach auf das System bannen. [/Update 07.04.2014 PDFCrop ist sowohl bei Debian wie auch Ubuntu im Paket texlive-extra-utils enthalten, so dass sich das Skript auch unten Debian-Distributionen sehr einfach installieren lässt. Den nachfolgenden Part könnt ihr also ignorieren, wenn ihr euch via „sudo apt-get install texlive-extra-utils“ PDFcrop aus der Paketverwaltung installiert.]
Dazu installiert ihr mit pdftk die einzige Abhängigkeit — was meist noch einen langen Rattenschwanz an Paketen mit sich zieht — und ladet dann das Skript aus dem entpackten Archiv pdfcrop_v0.4b.tar.gz nach /usr/local/bin und macht es abschließend ausführbar. Wer mit Arch Linux arbeitet, der hat es jedoch leichter: Wie so oft findet sich bei dieser genialen Distribution die gesuchte Software unter dem gleichnamigen Paket im AUR.
# PDFCrop unter Ubuntu/Debian installieren... $ sudo apt-get install pdftk $ wget http://sourceforge.net/projects/pdfcrop/files/pdfcrop/PDFCrop%20v0.4b/pdfcrop_v0.4b.tar.gz $ tar xzf pdfcrop_v0.4b.tar.gz $ sudo cp pdfcrop_v0.4b/pdfcrop /usr/local/bin $ sudo chmod +x /usr/local/bin/pdfcrop # PDFCrop unter Arch Linux installieren... $ pacaur -S pdfcrop
Nun könnt ihr PDFCrop auch schon aufrufen, als Parameter gebt ihr das zu verarbeitende PDF und den Namen der überarbeiten Datei an. Alternativ könnt ihr dem Kommando zwischen den Dateinamen auch noch das Format des resultierendes PDFs mitgeben, PDFCrop spuckt „Letter“, „Legal“ und „A4“ aus, wobei hierzulande wohl nur DIN-A4 von Interesse sein wird.
$ pdfcrop input.pdf output.pdf $ pdfcrop input.pdf A4 output.pdf
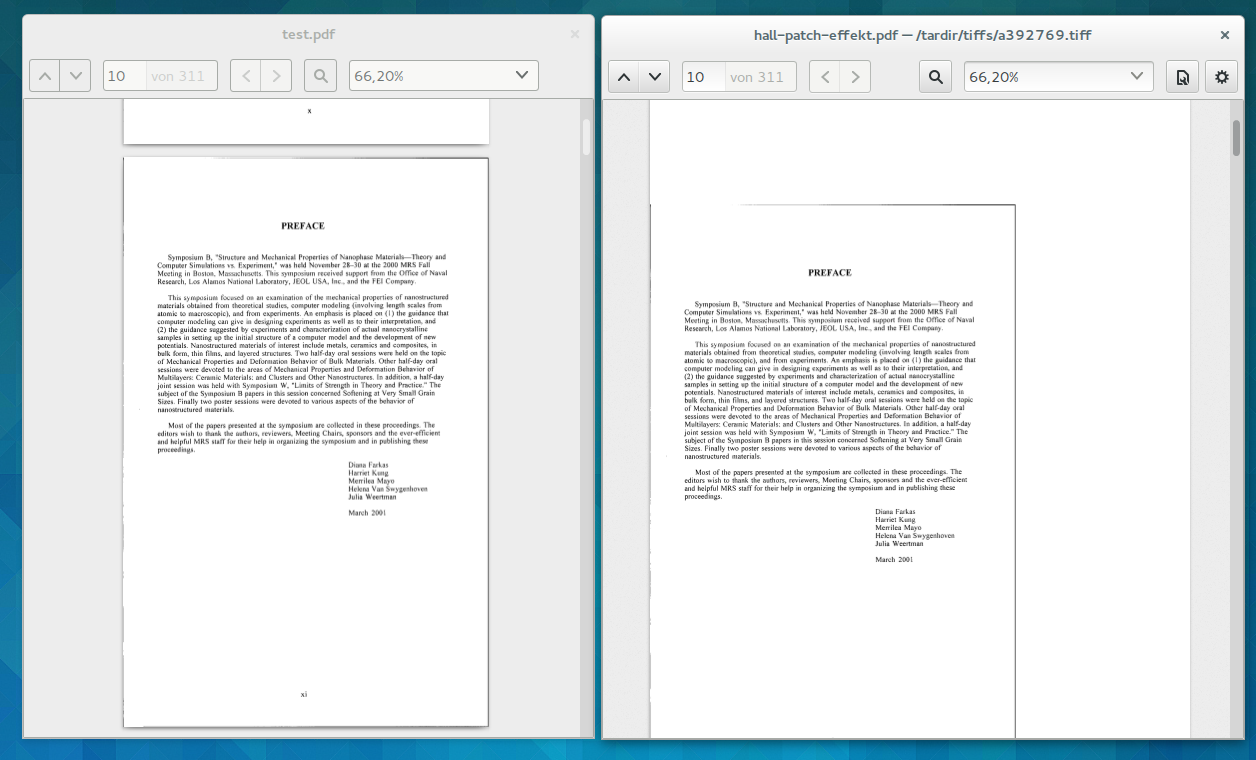
Ein Beispiel könnt ihr im folgenden Sehen. Das PDF-Dokument hat über 300 Seiten und wurde in nur knapp 30 Sekunden — allerdings auf einem Core i7 — auf ein brauchbares Format zurechgeschnitten, ohne dass ich auch nur einen Finger krumm machen musste. Auf einem langsameren Rechner kann das Zuschneiden etwas länger dauern, allerdings könnt ihr euch während dessen anderen Aufgaben widmen.
Im Stapel zuschneiden mit Briss oder PDF-Quench
Stellt euch das automatisch generierte Ergebnis von PDF-Crop nicht zufrieden, dann könnt ihr im weiteren Verlauf zu Briss oder PDF-Quench greifen. Beide Programme öffnen PDFs und lassen euch dann einen Rahmen um den Inhalt ziehen, auf den der Inhalt des PDF-Dokuments zurechtgeschnitten werden soll. Beide Anwendungen findet ihr unter Debian/Ubuntu — mal wieder — nicht in den Paketquellen, daher müsst ihr sie — mal wieder 😉 — von Hand auf den Rechner kopieren.
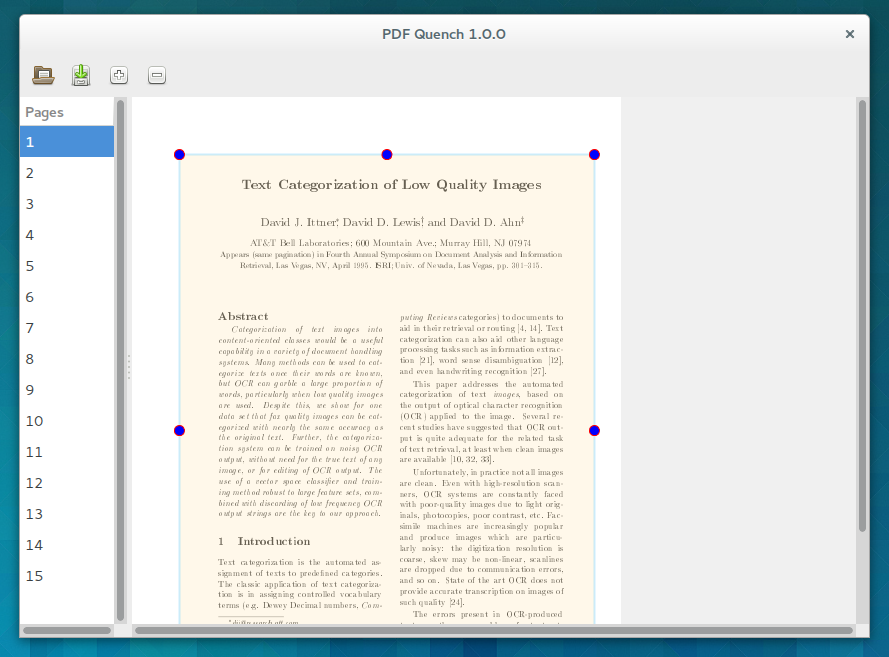
Von PDF-Quench findet ihr auf der bei Google-Code gehosteten Projektseite des Programms .DEB-Pakete, die sich unter Ubuntu oder auch Debian installieren lassen müssten können — getestet habe ich dies jedoch nicht. Briss dagegen ist als JAVA-Programm unter jedem System lauffähig (auch Windows), muss allerdings von Hand auf Debian-Systeme kopiert werden. Für Arch Linuxer ist das Leben — mal wieder — einfacher, sie installieren sich Briss und PDF-Quench einfach aus dem Arch-Linux-AUR — Habe ich schon gesagt, dass ich Arch einfach spitze finde?
# Briss unter Ubuntu/Debian aufrufen... tar xzf briss-0.9.tar.gz java -jar briss-0.9/briss-0.9.jar
# Briss/PDF-Quench unter Arch Linux installieren... $ pacaur -S briss $ pacaur -S pdf-quench
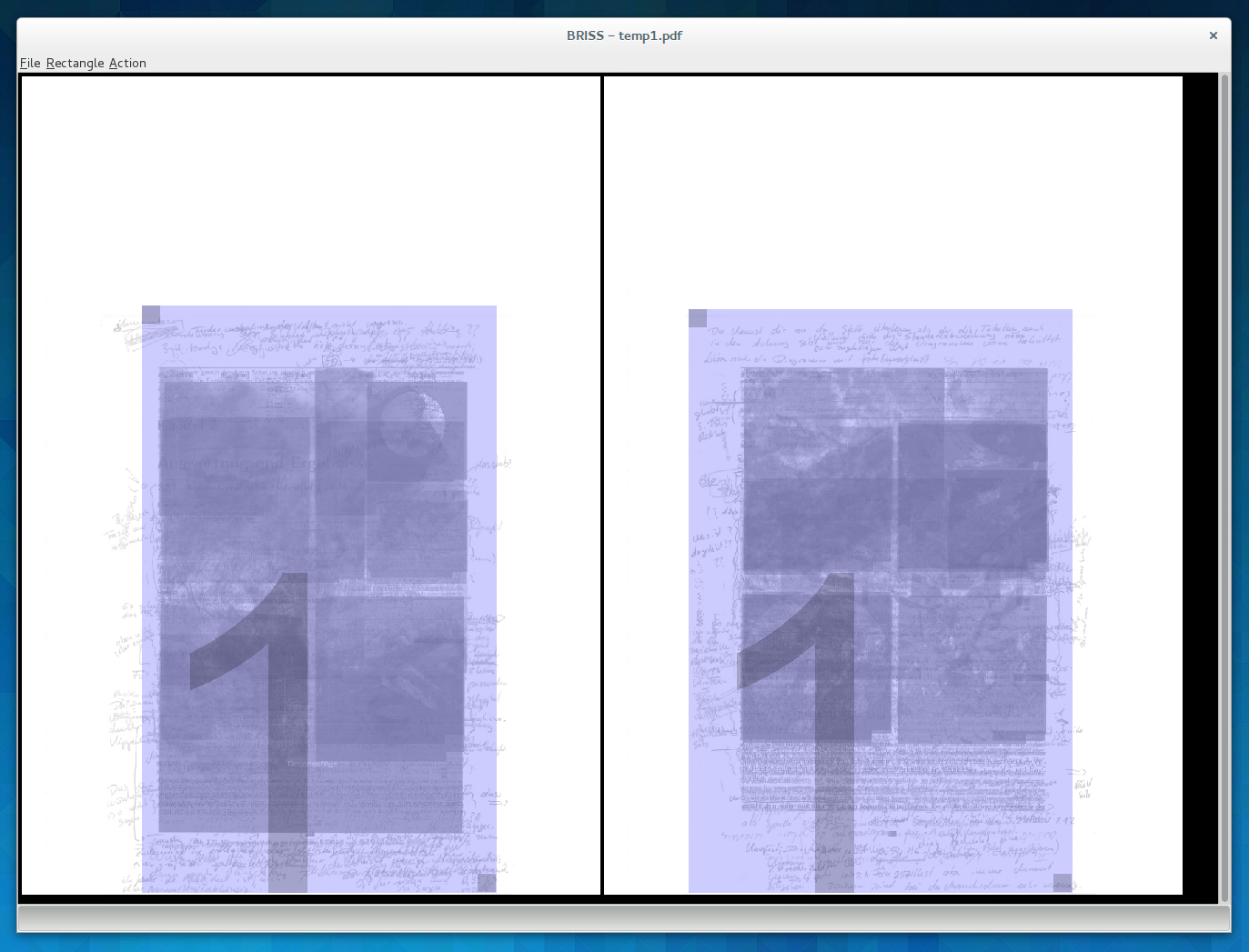
Briss und PDF-Quench ähneln sich von der Bedienung sehr: Ihr ladet in beide Apps euer PDF, markiert den herauszuschneidenden Bereich und speichert das zurechtgeschnittene Dokument ab — Fertig ist der Salat. Während PDF-Quench mit seiner rudimentären GTK-Oberfläche vielleicht ein bisschen „linuxiger“ aussieht, ist Briss vielleicht ein bisschen besser für seine Aufgabe geeignet. Briss legt alle Seiten des PDFs übereinander, so dass man sehr gut sehen kann, wo man nun die Schere ansetzen muss.
PDF sortieren mit dem PDFShuffler
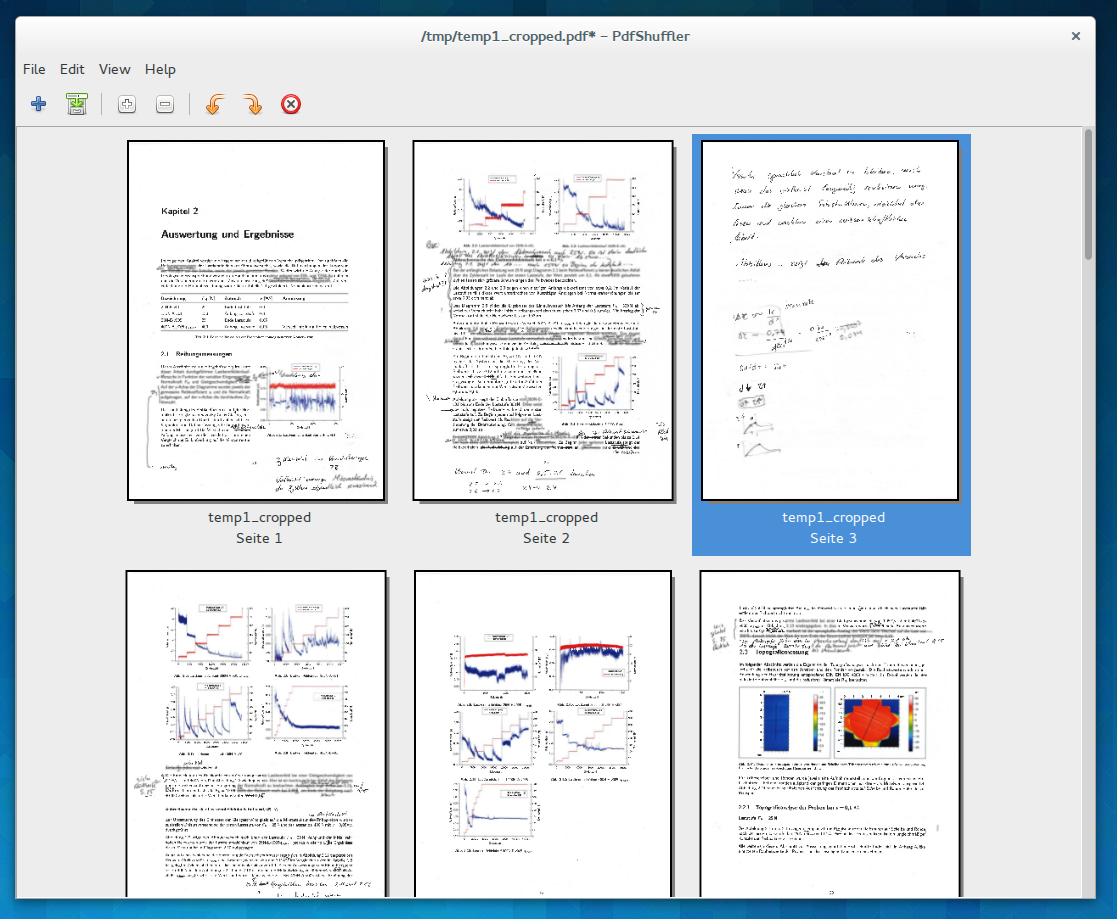
Nun ist euer PDF von unnötigen Whitespace befreit, allerdings kommt es durchaus öfters mal vor, dass die eine oder andere ungewollte Seite im PDF-Dokument steckt. Vielleicht hab ihr ja Vor- und Rückseite einscannen lassen, obwohl doch nur die Vorderseite eures Skripts bedruckt ist und nur ab und an etwas auf der Rückseite vermerkt wurde. Die unnützen Seiten sollen nun auch weg, am einfachsten geht dies mit PDFMod oder auch dem PDF-Shuffler, beide Programme habe ich ja auch schon einmal beim Thema Bewerben mit LaTeX angesprochen, daher erspare ich mir an dieser Stelle großartige weiterführende Erklärungen. Wer zu faul zum Nachlesen ist, der bekommt via…
# PDF-Shuffler/PDFMod unter Debian/Ubuntu installieren $ sudo apt-get install pdfshuffler $ sudo apt-get install pdfmod # PDF-Shuffler/PDFMod unter Arch Linux installieren $ sudo pacman -S pdfmod $ pacaur -S pdfshuffler
…beide Programme auf den Rechner und sucht sich dann die Anwendung heraus, Alternativ gibt es mit PDF Chain noch einen weiteren „PDF-Sortierer“ (@Andreas, danke für den Tipp), allerdings habe ich diesen noch nicht selber ausprobiert, bei mir kommt für diese Aufgabe meist der PDFShuffler zum Einsatz.









Super Zusammenfassung!
Was mich noch total interessieren würde – es hält mich vom Umstieg auf Linux am Desktop ab: Wie kann man unter Linux vorzugsweise GNOME schnell und elegant PDFs anotieren, also Textfelder, Zeichnen usw. bzw. welcher Reader stellt das überhaupt dar?
Okular macht mich leider absolut nicht glücklich…
Funktioniert perfekt unter Wine PDF XChange Viewer: http://wiki.ubuntuusers.de/PDF_XChange_Viewer
Scan Tailor ist ein schönes Tool zum Bearbeiten von Bücherscans.
Für mein „papierloses“ Büro arbeite ich seit ca. 2 Jahren sehr gerne mit gscan2pdf.
Dies enthält auch crop (auch für multiple Seiten), sortieren, Whitespace entfernen (ist bei mir aber buggy) und noch ein paae weitere kleinere nützliche Funktionen (u.a. OCR via Tesseract).
Man kann PDFs auch im Nachhinein (nach dem Scannen) öffnen.
Wenn man sich an ein paar Unstimmigkeiten im Programm gewöhnt hat 😉 ist es sehr hilfreich.
Bye, Patrick
Ja, gscan2pdf ist sehr gut, wenn man die PDFs noch weiterverarbeiten möchte. Unpaper ist allerdings in der Tat oft sehr „grob“, da sieht das unbehandelte Dokument meist noch besser aus.
Grüße
Christoph
Danke! Hab pdfcrop gerade über einen Haufen schlecht gescannter Arbeiten laufen lassen und der hat sie sauber zurechtgeschnitten. Danke für den Tipp! @Timo: Scan Tailer ist auch nicht schlecht!
Hi!
Finde krop sehr praktisch.
LG!
Briss wird weder unter Debian noch unter Fedora installiert. Einfach das Archiv entpacken, in den Ordner wechseln und
java -jar briss-0.9.jar
oder
java -jar briss-0.9.jar cropthis.pdf
ausführen. Steht alles in der README.txt. Funktioniert.
Steht auch im Beitrag 🙂
Hm.
Ahhh. OK. Das kommt davon, wenn man solche Bereiche copy&pasted 😉 ich andere das später. Danke für den Hinweis, Christoph.
Danke für die praktischen Hinweise.
Bei mir (Debian-Testing) ist PDF-Crop in dem Paket texlive-extra-utils enthalten.
Ah, danke! Ich hab die Information in den Artikel eingebaut! Christoph.