
Google besitzt in Deutschland in Bezug auf Suchmaschinenzugriffe einen schier unglaublichen Marktanteil von knapp 95 Prozent. Als Zweiter muss sich Microsofts Bing mit gerade einmal 2,5 Prozent vom Kuchen zufrieden geben, Yahoo folgt mit 2,0 Prozent dicht nach den Jungs aus Redmond. In anderen Worten: Wer in Deutschland etwas im Netz sucht, der googelt. Für Menschen die nicht möchten, dass Google jeden Suchbegriff erfährt und die Suchen am besten noch mit dem Gmail-Profil verknüpft, hat sich DuckDuckGo als Alternative etabliert. Doch es gibt auch im Open-Source-Bereich interessante Ansätze. Mit Searx könnt ihr eine eigene Metasuchmaschine betreiben, die sich individuell konfigurieren lässt. Auf Github findet ihr eine Liste mit Searx-Instanzen, die ihr zum Testen gerne mal ausprobieren könnt.
Für Searx reicht allerdings ein simpler Webspace mit PHP und Datenbank nicht aus, ihr braucht stattdessen einen kleinen Server mit der Möglichkeit Python-Programme ausführen zu können. Wer einen kleinen virtuellen Root-Server sein Eigen nennt, der kann sich Searx allerdings recht einfach aufsetzen — auch wenn ihr noch nicht so viel Erfahrung mit Python-Diensten gemacht habt. Der Vorteil an einer eigenen kleinen Searx-Instanz liegt darin, dass ihr der Allgemeinheit einen Dienst erweist und auch selber immer eine anonyme Suche an der Hand habt, die gar nicht mal so schlecht sortierte Ergebnisse liefert. Je mehr Searx-Installation sich im Netz tummeln, desto mehr Optionen gibt es für Anwender auch einmal anonym suchen zu können.
Searx unter Debian/Ubuntu installieren
Die Installation von Searx möchte ich hier an dieser Stelle gar nicht groß breittreten, da das Projekt in seinem Wiki eine erstklassige Schritt-für-Schritt-Anleitung auf seinen Github-Seiten pflegt und auch aktuell hält, die auch Einsteiger vor keine großen Hürden stellt. Würde ich diese Anleitung hier abtippen und sich etwas am Installationsprozess ändern, dann würdet ihr eventuell in einer Sackgasse stecken. Folgt daher bitte der Anleitung der Entwickler… es lohnt sich allerdings auf ein paar Punkte einzugehen, die mir während der Installation von Searx auf einem Debian Wheezy mit einem Apache als Webserver Schwierigkeiten gemacht haben. Die Tipps sollten sich allerdings auch auf einem Ubuntu-Server umsetzen lassen oder auch generell allgemein gültig sein. Aufrufe der Paketverwaltung müsstet ihr natürlich an die von euch genutzte Linux-Installation anpassen.

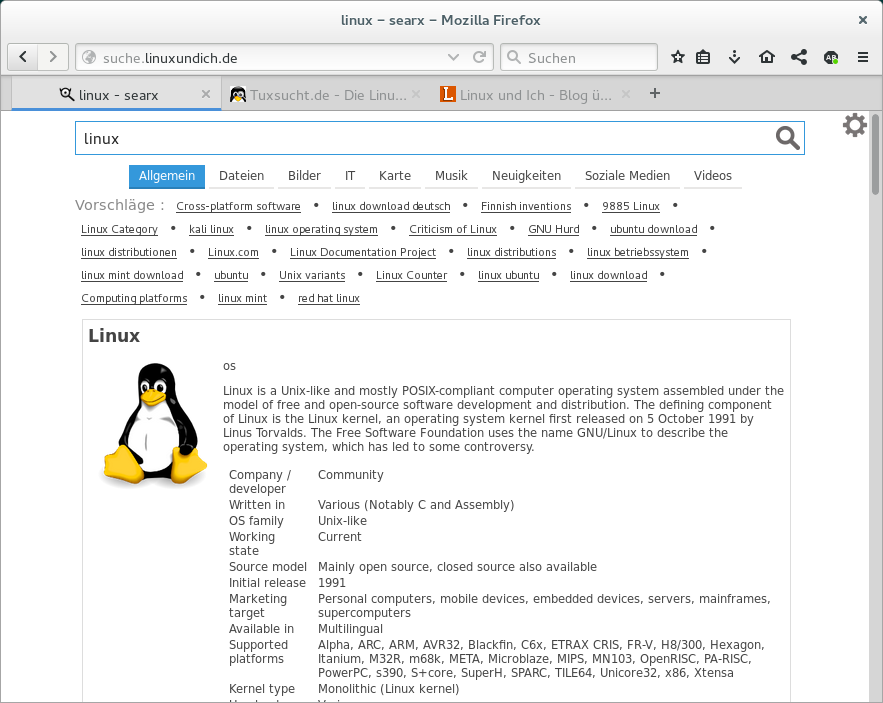

Die ersten Schritte entsprechend der basic installation und der configuration sollten euch eigentlich keine Probleme machen. Ich müsst wirklich einfach nur jeden Befehl ins Terminal des Servers kopieren und ausführen. Ihr installiert die benötigten Abhängigkeiten, ladet Searx per git nach /usr/local/searx und legt einen Benutzer an, unter dem die Anwendung später dann läuft. Danach installiert ihr die von Searx benötigten Python-Abhängigkeiten in eine eigene Virtualenv-Umgebungen und tragt per Sed-Kommando einen zufällig generierten Secret-Key in die Konfiguration ein. Anschließend könnt ihr Searx starten und zum ersten mal ausprobieren — Kleiner Tipp am Rande: Thomas hat in seinem Blog klasse Tipps gegeben, wie ihr Searx später einmal aktuell haltet.
### Startet Searx in einem ersten Terminal...
$ python searx/webapp.py
### Und ruft Searx dann vom Localhost aus auf...
$ sudo apt-get install links2
$ links2 http://localhost:8888Hier stolpert ihr nun eventuell zum ersten mal über ein kleines Problemchen. Ruft ihr die zum Test gestartete Searx-Instant über http://ip-oder-url-eures-servers:8888 in einem Browser auf, dann passiert erst einmal — rein gar nichts. Zweifelt nun bitte nicht an euren Fähigkeiten, sondern probiert es mit einem Textbrowser wie Lynx oder Links2 einfach von einem zweiten Terminal direkt auf dem Server aus. Searx lauscht nämlich nur auf Verbindungen vom Localhost, ruft ihr den Port von einem anderen Rechner aus ab, dann antwortet Searx nicht und ihr bekommt eine Fehlermeldung, dass hier nichts gefunden werden kann.
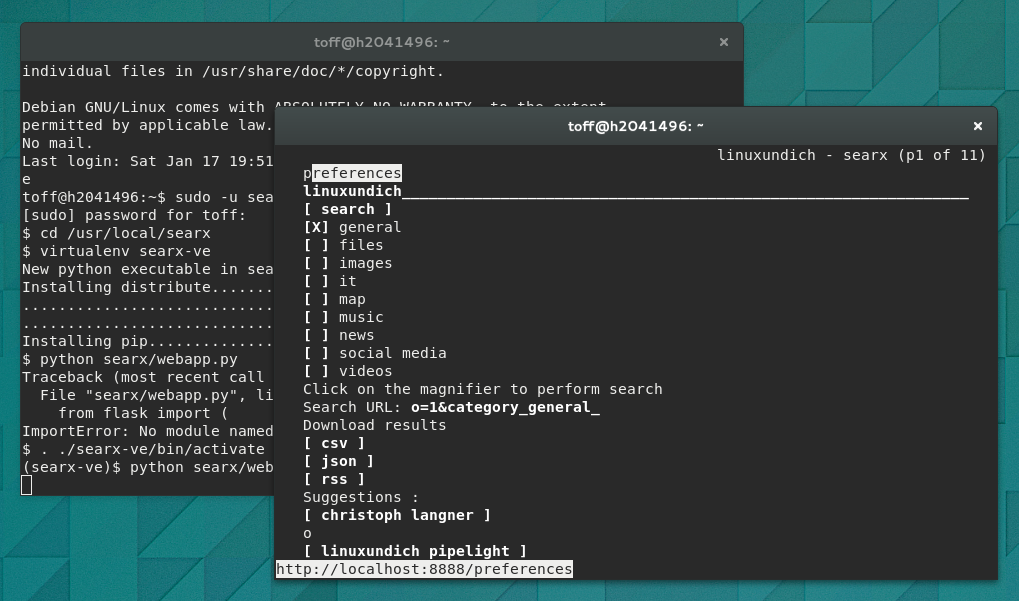
Klappt der Aufruf, dann habt ihr Searx erfolgreich installiert. Allerdings müsstet ihr das Python-Skript immer von Hand ausführen und würdet es auch nur auf dem Port 8888 erreichen. Mit uWSGI packt ihr das Skript daher in einen Container, den später den Webserver bei Bedarf ausführen kann. Sämtliche Informationen dazu liefert euch weiterhin die Schritt-für-Schritt-Anleitung des Searx-Wikis. Ich habe in der /etc/uwsgi/apps-available/searx.ini lediglich noch die Pfade ein wenig erweitert und die Anzahl der Worker-Threads reduziert, mein kleiner Rootie hat nämlich nur zwei Kerne.
[uwsgi]
# Who will run the code
uid = searx
gid = searx
# Number of workers
workers = 2
# The right granted on the created socket
chmod-socket = 666
# Plugin to use and interpretor config
single-interpreter = true
master = true
plugin = python
# Application base folder
base = /usr/local/searx/
# Module to import
module = searx.webapp
# Virtualenv and python path
virtualenv = /usr/local/searx/searx-ve/
pythonpath = /usr/local/searx/
chdir = /usr/local/searx/searx/
# The variable holding flask application
callable = appSolltet ihr nach dem Einrichten von uWSGI nun nochmal auf die Idee kommen eure Installation zu testen, dann wundert euch bitte nicht, dass ihr jetzt auch auf dem Localhost im Textbrowser Searx nicht mehr erreichen könnt. Keine Angst, ihr habt nichts kaputt gemacht, ihr müsst nun zwingend euren Webserver so konfigurieren, dass er Anfragen an Searx durchreicht. Ich für meinen Teil habe das Ganze entsprechend der Schritt-für-Schritt-Anleitung mit Apache umgesetzt, ihr könntet für diese Aufgabe allerdings auch auf Nginx zurückgreifen — diese Weg habe ich allerdings nicht selber ausprobiert.
Metasuchmaschine zum selber hosten
Die nächsten Schritte hängen nun davon ab, ob Searx die einzige Webseite sein soll, die auf eurem Serverchen läuft, oder ob Searx auf einer Subdomain zu erreichen sein soll. Ich für meinen Teil habe mich für den zweiten Weg entschieden, da auf meinen Server noch anderen Seiten aktiv sind und weiterhin erreichbar sein sollen. Möchtet ihr allerdings Searx exklusiv betreiben, dann tragt einfach in die /etc/apache2/sites-available/default die in der Anleitung genannten Apache-Optionen ein. Auf einem nicht groß veränderten System würde die Datei in etwa so aussehen.
<VirtualHost *:80>
ServerAdmin webmaster@localhost
AllowEncodedSlashes On
<Location />
Options FollowSymLinks Indexes
SetHandler uwsgi-handler
uWSGISocket /run/uwsgi/app/searx/socket
</Location>
DocumentRoot /var/www
<Directory />
Options FollowSymLinks
AllowOverride None
</Directory>
[...]Wollt ihr wie ich Searx auf einer Subdomain betreiben, dann müsst ihr einen Virtual Host erstellen. Dazu legt ihr den Vhost über die Datei /etc/apache2/sites-available/searx an (den Dateinamen könnt ihr frei wählen) und übernehmt die folgende Konfiguration. Den Servernamen müsst ihr dabei selbstverständlich an eure Domain anpassen. Die restlichen Einträge könnt ihr ansonsten exakt so übernehmen. Am Ende aktiviert ihr den Vhost mit a2ensite und lasst den Apache-Webserver seine Konfiguration neu einlesen.
<virtualhost *:80>
ServerName suche.linuxundich.de
ServerAdmin webmaster@localhost
<Location />
Options FollowSymLinks Indexes
SetHandler uwsgi-handler
uWSGISocket /run/uwsgi/app/searx/socket
</Location>
ErrorLog ${APACHE_LOG_DIR}/error.log
LogLevel warn
CustomLog ${APACHE_LOG_DIR}/access.log combined
</virtualhost>
$ sudo a2ensite searx
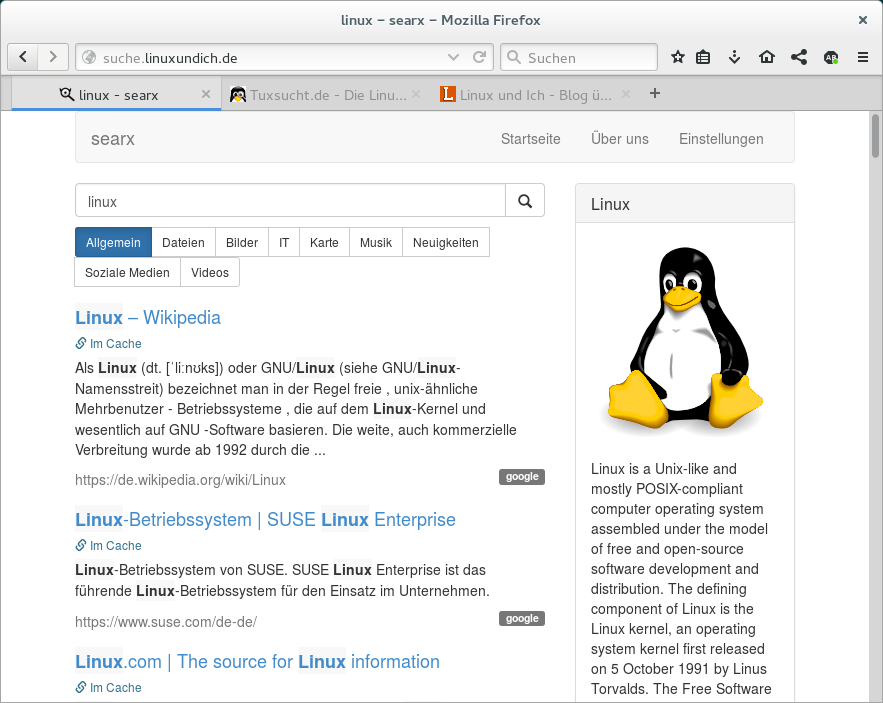
$ sudo service apache2 reloadNun müsstet ihr eure Searx-Instanz unter http://eure-domain.de oder eben http://subdomain.eure-domain.de erfolgreich aufrufen können. Die Bedienung der Metasuchmaschine sollte euch nun nicht weiter schwer fallen, einfach einen Suchbegriff eintippen und mit Return lossuchen — Searx durchstöbert dann Google, Bing, Yahoo, DuckDuckGo und noch viele Dienste mehr und gibt die aggregierten Ergebnisse individuell sortiert aus. Dabei fließen keine Daten zwischen euch und den abgefragten Suchanbietern, Searx kommuniziert stattdessen mit diesen. Google kann also höchstens ein Profil über die gesamte Searx-Instanz erstellen.
In den Einstellungen gebt ihr vor, welche Suchsprache Searx bevorzugen soll, ob die Suchbegriffe per Google, DuckDuckGo, DBPedia oder Wikipedia vervollständigt werden sollen und welches Theme Searx bei euch nutzen soll, drei verschiedene Looks stehen zur Wahl. Am besten sieht in meinen Augen Oscar aus, allerdings benötigt das Template zwingend aktiviertes JavaScript. Das ist beim Standard-Theme nicht der Fall, daher lasse ich dieses auch weiterhin als Vorgabe aktiv. Die Einstellungen speichert Searx bei euch auf individuell als Cookie ab, so bleiben die Einstellungen auch erhalten.
HINWEIS: Ich lasse Searx in Zukunft bei mir auf meinen Root-Serverchen laufen. Möchtet ihr also ab und an mal ohne Google-Beobachtung, ohne Anzeigen und ohne Tracking etwas im Netz suchen, dann könnt ihr gerne auf suche.linuxundich.de zurückgreifen. Ich werde meine Searx-Instanz aktuell halten und vielleicht in Zukunft auch noch meine Linux-Suche Tuxsucht.de integrieren. Dazu muss ich mich allerdings noch ein wenig mehr in die Thematik reinfuchsen. //UPDATE: Inzwischen ist das Projekt gestorben und ich habe das Hosting eingestellt.
Die Suche lässt sich auf zwei Arten einschränken: Im Hauptscreen könnt ihr zwischen Allgemein, Dateien, Bildern, Karten und Co wählen und so die Ergebnisse ein wenig nach euren Wünschen ausfiltern. Alternativ geht ihr abermals in die Einstellungen und de-/aktiviert einzelne Suchmaschinen, deren Ergebnisse Searx gezielt aggregieren oder eben links liegen lassen soll. Auch diese Einstellungen sichert Searx wieder für jeden Anwender individuell als Cookie. Global könntet ihr die einzelnen Suchmaschinen in der Konfigurationsdatei von Searx /usr/local/searx/searx/settings.yml ausklammern. Hier ließen sich auch weitere Suchmaschinenanbieter hinzufügen, ganz so einfach ist dies allerdings nicht.










Also ich finde das Konzept von Yacy besser, da man dort sogar selbst indexiert und das der community bereitstellen kann. Metasuchen wie searx nutzen ja auch wiederrum Google und Co. So bleibt man weiter abhängig von Großkonzernen. Nachteil an Yacy mMn: Java. Python ist dann doch irgendwie hübscher. ^^
Yacy ist alles andere als trivial aufzusetzen. Ich probiere mich schon eine ganze Weile da dran. Ziel ist es tuxsucht.de auf Yacy umzustellen, allerdings schaffe ich es bisher nicht die Ergebnisse sinnvoll gewichtet ausgeben zu können. Meine Test-Installation kannst du unter http://linuxandi.net:8090 ansehen. Suchst du bspw. nach „Linux“, dann bekommst du haufenweise Index- und Kategorie-Seiten zu Gesicht. An der Feinabstimmung des Rankings hab ich schon x Stunden verschwendet. Des weiteren kannst du auf einem kleinen Vserver wohl kaum das Internet indexieren. Dafür brauchst du die Ressourcen eines Weltkonzerns.
Danke für den Beitrag! Hab gleich mal bei mir eine Instanz aufgesetzt. Ging deutlich stressfreier als Yacy, und den Aggregatorgedanken dahinter finde ich richtig klasse.
Sehr interessant! Werde die Tage auch mal eine Instanz auf meinem Server aufsetzen…
Was ich aber bei allen Ausflügen zu startpage.com, duckduckgo.com und anderen immer wieder feststelle: Die Relevanz der Trefferliste von Google ist unerreicht! Ich suche sehr viel IT- und Pythonkram. Wenn ich dabei von einer Alternativmaschine keine wirkliche Hilfe angeboten bekomme, greife ich dann doch immer wieder mal gerne auf Google zurück…
Nichtsdestotrotz: Alternativen wie Searx müssen unbedingt unterstützt werden, damit wir nicht irgendwann einmal mit Google allein ins Bett müssen!
Claus
Alles ist besser als Go…. !
Habe mir einfach ein Lesezeichen hinzugefügt.
Interessanter Artikel, Danke!
Hat jemand schon eine Lösung für das opensearch.xml Problem gefunden?
Möchte meine searx-Seite der Firefox-Suche hinzufügen. Leider ohne Erfolg, da immer eine Fehlermeldung erscheint.
Folgende Lösung war bereits bei mir aktuell vorhanden
https://github.com/asciimoo/searx/commit/8cd7617054d5290cc02a1d2ee08703e10d6e7f28
Strange, ich hab meine Searx-Instanz mit Firefox 35.0.1 getestet, da funktioniert es ohne Probleme und ohne, dass ich etwas basteln musste. Funktioniert es bei dir hier suche.linuxundich.de?
Bei dir funktioniert es wunderbar.
Ich nutze jedoch eine HTTPS-Verbindung…
https://searx.danny-korpan.de/
Hi Danny, wenn ich dir Suche, dann bekomme ich erst gar keine Ergebnisse. Searx rotiert ewig und meldet dann am Ende „Entschuldigung! Es konnten keine Suchergebnisse gefunden werden. Bitte nutze einen anderen Suchbegriff, oder suche das gewünschte in einer anderen Kategorie. “ und das bei einer Suche nach „test“.
Hatte gerade den Server neu gestartet… ggf. hattest du deshalb gerade ein Problem.
Jetzt tut die Suche wieder, bekomme beim Hinzufügen der Suchmaschine in Firefox jetzt die Meldung: Firefox konnte die Suchmaschine nicht herunterladen von: https://searx.danny-korpan.de/opensearch.xml. Ich denke, das ist das Problem. Hast du dich mal an https://github.com/asciimoo/searx/issues gewendet? Als ich Searx eingerichtet habe, bin ich über einen Bug gestolpert, den die Jungs im Nullkommanix behoben hatten — und wo ich dachte, dass ich nen Fehler gemacht hatte.
Deine Suchmachine unter http://suche.linuxundich.de/ ist nicht mehr erreichbar. Ist das Absicht? Ich suchte immer hier, wenn Google wieder nur Müll ausspuckte.
Hi Markus, da muss was bei einem Upgrade schief gelaufen sein. Ich kümmere mich Anfang der Woche drum. Danke für den Hinweis. Grüße Christoph.
Hi Markus, bad news: Das Ding lief auf einem Testserver, den es zerschossen hat und den ich nicht wieder erneuern werde. Da mir so nun ein Root-Server fehlt, wird es die Suche wohl nicht mehr geben. Sorry, Christoph.
Hallo,
kannst du bitte deinen Text anpassen:
Unter suche.linuxundich.de könnt ihr Searx gerne einmal ausprobieren.
verweise z.b auf https://github.com/asciimoo/searx/wiki/Searx-instances
danke im voraus
pic
Hab den Beitrag aktualisiert. Grüße, Christoph