
Daten können auf unterschiedliche Art und Weise verloren gehen: Kaputte Massenspeicher (egal ob Festplatte oder SSD), zerschossene Dateisysteme, Verlust des Notebooks oder Smartphones durch Diebstahl oder Schusseligkeit, sowie die eigene Dummheit beim versehentlichen Löschen von Daten. Gegen allzu dramatische Datenverluste infolge dieser unglücklichen Ereignisse helfen in der Regel Backups, die eigentlich jeder Computeranwender regelmäßig erstellen sollte — was bekanntlich aber nur ein Bruchteil aller User macht. Gegen eine weitere Form des Datenverlusts helfen jedoch auch Backups nur bedingt. Silent Data Corruption oder Bitrot schlägt unmerklich zu, da nur einzelne Bits einer oder mehrere Dateien betroffen sind. Moderne Dateisysteme wie Btrfs oder ZFS schützen in einem RAID-Verbund mit Prüfsummen zu Daten und Metadaten gegen Bitrot. Doch wie dramatisch ist das Problem eigentlich? Ich schaue mir von Bitrot befallene JPG-Dateien einmal genauer an.
Bitrot schummelt Fehler leise ins Dateisystem
Unter Bitrot bezeichnet man umgangssprachlich das „Kippen“ einzelner Datenbits. Dies kann etwa bei Zahlen schnell dramatische Folgen hervorrufen: Habt ihr etwa 100 Euro auf dem Konto (Binär: 1100100) und das erste Bit kippt in der Datenbank der Bank zu einer 0, dann schrumpft euer Guthaben auf einen Schlag auf nur noch 36 Euro (Binär: 0100100). Damit dies nicht passiert, speichern moderne Dateisysteme Daten redundant und schreiben Prüfsummen, sodass man zum einen merkt, dass etwas mit den Daten nicht stimmt und zum anderen sie auch automatisch wiederherstellen kann. Auch Dateiformate selber besitzen eine gewisse Redundanz, sodass kleine Datenfehler im Bild eigentlich kaum ersichtlich sein sollten. Daher hat mich dieser Beitrag von Ars Technica sehr gewundet. Schon nach drei gekippten Bits ist das dort gezeigte Bild nicht mehr erkennbar. Gut, nach 10 gekippten Bits bin ich auch nicht mehr wiederzuerkennen, aber der Totalausfall nach 3 gedrehten Bits macht einem schon Sorgen — schließlich gehören Bilder für viele von uns zum wertvollsten Datenschatz.
Um das Thema also einmal selber nachzustellen, braucht es ein Bild und ein kleines Programm, mit dem man gezielt einzelne Bits einer Datei umkippen lassen kann. Im Netz finden sich dazu eine Reihe von kleinen Code-Schnippseln, der folgende in Python geschriebene Code macht als bitflip.ph abgespeichert genau dies. Als Parameter übergebt ihr den Programm einen Offsetwert, also im Endeffekt das wie vielte Bit es drehen soll. Zudem habe ich mit bitflip.sh ein kleines Shell-Skript geschrieben, das automatisiert eine beliebige Anzahl an Bits einer Datei drehen kann. Es nummeriert zudem die einzelnen Bilder und erstellt am Ende aus den Einzelbildern ein Video — mit dem Ziel am Ende den Verfall des Bildes als animierten Verlauf zu sehen.
Skripte zum automatisierten Drehen einzelner Bits
bitflip.ph
#!/usr/bin/python """Toggle the bit at the specified offset. Syntax: filename bit-offset""" import sys fname = sys.argv[1] # Convert bit offset to bytes + leftover bits bitpos = int(sys.argv[2]) nbytes, nbits = divmod(bitpos, 8) # Open in read+write, binary mode; read 1 byte fp = open(fname, "r+b") fp.seek(nbytes, 0) c = fp.read(1) # Toggle bit at byte position `nbits` toggled = bytes( [ ord(c)^(1<<nbits) ] ) # print(toggled) # diagnostic output # Back up one byte, write out the modified byte fp.seek(-1, 1) # or absolute: fp.seek(nbytes, 0) fp.write(toggled) fp.close()
bitflip.sh
#!/bin/bash
# Settings
ORIGFILE=$1
FIRSTBIT=$2
LASTBIT=$3
STEPWIDTH=$4
# Folders
FLIPPEDFILES=tmp_flipped
VIDEOTEMP=tmp_video
# Init
FLIPPEDBITS=0
# Watch for Ctrl+C
trap "exit" INT
# Prepare
if [[ ! -e $FLIPPEDFILES ]]; then
mkdir $FLIPPEDFILES
else
rm $FLIPPEDFILES/*
fi
if [[ ! -e $VIDEOTEMP ]]; then
mkdir $VIDEOTEMP
else
rm $VIDEOTEMP/*
fi
# Function annotate
function annotate () {
convert $1/$2.jpg -gravity southeast \
-stroke '#000C' -pointsize 100 -strokewidth 2 -annotate 0 $3 \
-stroke none -pointsize 100 -fill white -annotate 0 $3 \
$1/$2.jpg
}
# Flip bits
cp $ORIGFILE $FLIPPEDFILES/$FIRSTBIT.jpg
convert $ORIGFILE $FLIPPEDFILES/$FIRSTBIT.jpg +append $VIDEOTEMP/$FIRSTBIT.jpg
while [ $FIRSTBIT -lt $LASTBIT ]; do
echo Flipping bit: $FIRSTBIT
echo Flipped bits: $FLIPPEDBITS
let PLUSONE=FIRSTBIT+STEPWIDTH
cp $FLIPPEDFILES/$FIRSTBIT.jpg $FLIPPEDFILES/$PLUSONE.jpg
./bitflip.py $FLIPPEDFILES/$PLUSONE.jpg $PLUSONE
convert $FLIPPEDFILES/$FIRSTBIT.jpg $FLIPPEDFILES/$PLUSONE.jpg +append $VIDEOTEMP/$PLUSONE.jpg
annotate $VIDEOTEMP $PLUSONE $FLIPPEDBITS
let FIRSTBIT=FIRSTBIT+STEPWIDTH
let FLIPPEDBITS=FLIPPEDBITS+1
clear
done
# Build video
cd $VIDEOTEMP
cat *.jpg | ffmpeg -y -f image2pipe -r 15 -vcodec mjpeg -i - -vcodec libx264 ../out.mp4
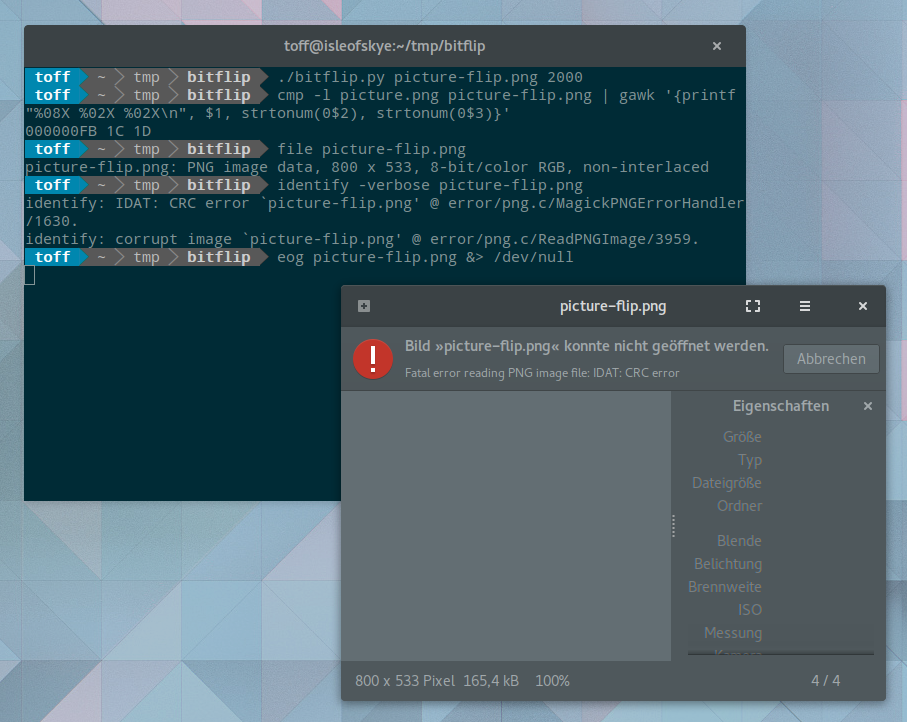
Doch bevor ich das Skript auf ein JPG loslasse, muss bitflip.ph beweisen, ob es auch wirklich funktioniert. Dazu nehme ich ein beliebiges PNG-Bild und flippe gezielt ein einzelnes Bit. Ein binärer Verglich mit cmp zeigt dann den Unterschied. Der Aufruf von file erkennt anschließend zwar noch eine PNG-Datei, doch ein Bildbetrachter mag die Datei nicht mehr öffnen, wie auch identify aus der Imagemagick-Suite einen mit IDAT: CRC error einen Fehler in der Bilddatei meldet. Schalte ich das Bit erneut um, dann akzeptiert identify das Bild wieder brav und der Bildbetrachter von Gnome öffnet die PNG-Datei ebenfalls wieder. Summa summarum: Schon ein gekipptes Bit kann eine Datei komplett runinieren. JPG bringt jedoch deutlich mehr Redundanzen mit, von daher bin ich gespannt, wie sich das für Fotografien übliche Dateiformat schlägt.
### Beliebige PNG-Datei kopieren
$ cp picture.png picture-flip.png
### Als Beispiel das 2000. Bit flippen
$ ./bitflip.py picture-flip.png 2000
### Hat es geklappt, ja!
$ cmp -l picture.png picture-flip.png | gawk '{printf "%08X %02X %02X\n", $1, strtonum(0$2), strtonum(0$3)}'
000000FB 1C 1D
### Immer noch eine PNG-Datei? $ file picture-flip.png picture-flip.png: PNG image data, 800 x 533, 8-bit/color RGB, non-interlaced ### Bild-Information kaputt $ identify -verbose picture-flip.png identify: IDAT: CRC error `picture-flip.png' @ error/png.c/MagickPNGErrorHandler/1630. identify: corrupt image `picture-flip.png' @ error/png.c/ReadPNGImage/3959.
### Gegenprüfung, wieder das 2000. Bit flippen $ ./bitflip.py picture-flip.png 2000 ### Bild-Informationen stimmen wieder $ identify -verbose picture-flip.png Image: picture-flip.png Format: PNG (Portable Network Graphics) Mime type: image/png Class: DirectClass Geometry: 800x533+0+0 Resolution: 28.35x28.35
Bei Ars schildert Autor Jim Salter nun, dass es schon mit einem geflippten Bit im JPG-Bild Artefakte erscheinen. Nach zwei und erst recht nach drei gekippten Bits ist dann kaum mehr etwas von dem Originalbild zu erkennen. In meinen Tests kann ich das nun aber nicht nachvollziehen: Mein Testbild bleibt ein Bild und für das Auge ergibt sich kein erkennbarer Unterschied, nur cmp meldet (wie gewünscht) die Anzahl der Unterschiede in den jeweiligen Dateien. Ich habe den Vergleich bewusst auf eine „richtige“ Fotografie beschränkt und nicht auf eine künstlich kleine JPG-Datei, da natürlich die Redundanz mit der Größe des Bildes zunimmt. 1000 gekippte Bits in einer 1 Kb großen Datei dürften sich deutlich dramatischer Auswirken als in einer 5 Mb großen Datei, frisch von der Digitalkamera geladen.
Mit 10 gekippten Bits
$ cmp -l ../katze_orig.jpg 11000.jpg | gawk '{printf "%08X %02X %02X\n", $1, strtonum(0$2), strtonum(0$3)}' | wc -l
10

Mit 100 gekippten Bits
$ cmp -l ../katze_orig.jpg 20100.jpg | gawk '{printf "%08X %02X %02X\n", $1, strtonum(0$2), strtonum(0$3)}' | wc -l
100

Mit knapp 1000 gekippten Bits
$ cmp -l ../katze_orig.jpg 110000.jpg | gawk '{printf "%08X %02X %02X\n", $1, strtonum(0$2), strtonum(0$3)}' | wc -l
999

Lange Rede, kurzer Sinn: Ganz so schlimm wie der Autor von Ars darstellt, wirkt sich Bitrot bei JPEG-Dateien nicht aus. Dennoch sollte man sich bei seiner Backupstrategie ein wenig Gedanken an die Tatsache verschwenden, dass einzelne Bits auf dem Datenträger kippen können. Sichert man nun einfach nur Stumpf seine Daten auf ein Backup-Medium, dann wandert der Defekt unbemerkt ins Backup und ersetzt auch irgendwann mal die älteste Version in der Sicherung, sodass eine Wiederherstellung zu einem späteren Zeitpunkt unmöglich wird. Dazu gehören moderne Dateisysteme, die Prüfsummen wie Btrfs oder ZFS für alle Daten anlegen (nicht nur wie Ext4 für das Journal) und am besten darunter noch ein RAID1, sodass man Daten leicht wiederherstellen kann.








")

Wie verhält es sich, wenn die Bits in der Prüfsumme des Dateisystems kippen und gar nicht in der Datei selbst? Dann helfen doch auch die Redundanzen von JPG nicht mehr, oder?
Wie funktioniert denn der Schutz mit z.B. Btrfs in der Praxis? Kann da ein regelmäßiger automatischer Dateisystemcheck gefahren werden, der Warnungen ausgibt? Ich stelle mir das relativ aufwendig vor, zumal wenn man sich kein RAID1 leisten will (SSD-Preise, Platzbedarf…).
@Wabbeldickwurst:
Btrfs und ZFS prüfen bei jedem Lesezugriff auf die Datei und korrigieren im Notfall.
Da man natürlich nicht alle Dateien ständig öffnet, kann man ein „scrubbing“ laufen lassen – automatisiert oder manuell. Dort werden alle Dateien und Prüfsummen gegeneinander abgecheckt.
RAID1 wäre nur eine zusätzliche Möglichkeit neben Backups die Datensicherheit zu erhöhen – und gegebenenfalls bei einem Plattenausfall ohne Datenausfall gleich weiterarbeiten zu können.
Danke. Das heißt, Btrfs kann aus der Checksumme und der korrumpierten Datei auch die Originaldatei errechnen (vermutlich nur, wenn die Datei nicht zu stark korrumpiert ist) und macht das automatisch? Das ist natürlich eine schöne Sache. Vielleicht schaue ich mir das mit Btrfs doch mal bei Gelegenheit an…
Meines Wissens helfen ZFS und BTRFS aber nur, wenn der Rechner, auf dem ganze läuft, auch mit ECC-RAM ausgestattet ist und CPU und Mainboard auch die ECC-Funktion unterstützen.
Hi! Nein, es geht ja nicht nur um den laufenden Betrieb, sondern auch um „flippende“ Bits, die sich drehen, wenn der Rechner gar nicht benutzt wird. Christoph.
So ganz sicher bin ich nun doch nicht, was die Korrektur unter Btrfs angeht. Hier zum Beispiel klingt es ja ganz so, als könne Btrfs mit Checksums lediglich Bit Rot erkennen, bräuchte aber zum Korrigieren dann eben eine redundante Speicherung (RAID1):
Von einem „Einzelfall“ (egal ob besonders gravierende bzw. unsichtbare Unterschiede) würde ich noch nicht auf die allgemeine Situation schließen.
Die Kompressionsstufe, Position der Fehlerbits und progressive Kompression sind vielleicht auch ausschlaggebend.
bitflip.ph oder bitflip.py? Wohl eher letzteres…
Sowohl ZFS alsauch BTRFS benötigen zur Korrektur jeweils eine zweite Ablage von Daten und Prüfcode, sei es ein Spiegel, ein RAID oder bei ZFS lokale Duplikate auf der Platte (doppelte Speicherung). Ich kann hier nur für ZFS sprechen, da ich BTRFS nicht genau kenne. Es wird der Prüfcode mit den Daten verglichen. Nur wenn der Prüfcode und die Daten zusammen passen sind die Daten OK. Genau da liegt der Unterschied zu den anderen Software- und Hardware RAID’s, die dies schlicht nicht korrekt können. Beide ZFS und BTRFS können Fehler erkennen und beheben. Vorsicht aber bei BTRFS. BTRFS ist im Gegensatz zu ZFS weitestgehend ein reines Dateisystem. Sowie man ein RAID unter BTRFS nutzt, sieht BTRFS die einzelnen Platten nicht mehr. Dies bedeutet, es kann zwar noch immer Fehler erkennen, aber eine Korrektur ist dann nicht möglich, weil es nur eine Variante der Daten und Prüfsummen sieht. BTRFS also erst mit RAID5 nutzen, wenn es auch in BTRFS implementiert ist.