
Im Beitrag zu tatort-dl und dem Download von Beiträgen aus der ARD-Mediathek wurde ich gefragt, ob es denn sowas nicht auch für die ZDF-Mediathek geben würde. Im Netz habe ich dazu zwar vereinzelte Code-Schnipsel gefunden, aber kein komplettes Skript. Daher möchte ich euch an dieser Stelle zdf-dl vorstellen. Das Skript arbeitet ähnlich wie tatort-dl, es lädt die entsprechende Seite aus der ZDF-Mediathek per Curl runter, filtert den Stream raus und lädt ihn dann per mplayer herunter. Am Ende habt Ihr dann eine Video-Datei, die Ihr mit jedem Player abspielen könnt.
Für das Skript habe ich bei GitHub ein entsprechendes Repository eingerichtet, aus dem Ihr euch gerne bedienen könnt, das Skript ist unter der recht freien Apache License, Version 2.0 lizenziert. Ich würde mich freuen, wenn Ihr weitere Ideen entweder direkt in das Git einpflegt, oder euch in den Kommentaren einbringt. Vielleicht lohnt es sich ja mal die ganzen Skripte in einer mediathek-dl Bibliothek zusammenzufassen.
$ sudo apt-get install curl mplayer
$ wget https://raw.github.com/linuxundich/zdf-dl/master/zdf-dl -O ~/bin/zdf-dl
$ chmod +x ~/bin/zdf-dlDie Installation des Skripts ist einfach: Holt euch das Skript aus dem Github, packt es nach ~/bin (legt das Verzeichnis an und startet euer Terminal neu, dann steckt das Verzeichnis umgehend in eurem $PATH) und setzt noch die entsprechenden Rechte. Danach könnt Ihr URLs aus eurem Browser dem Skript übergeben.
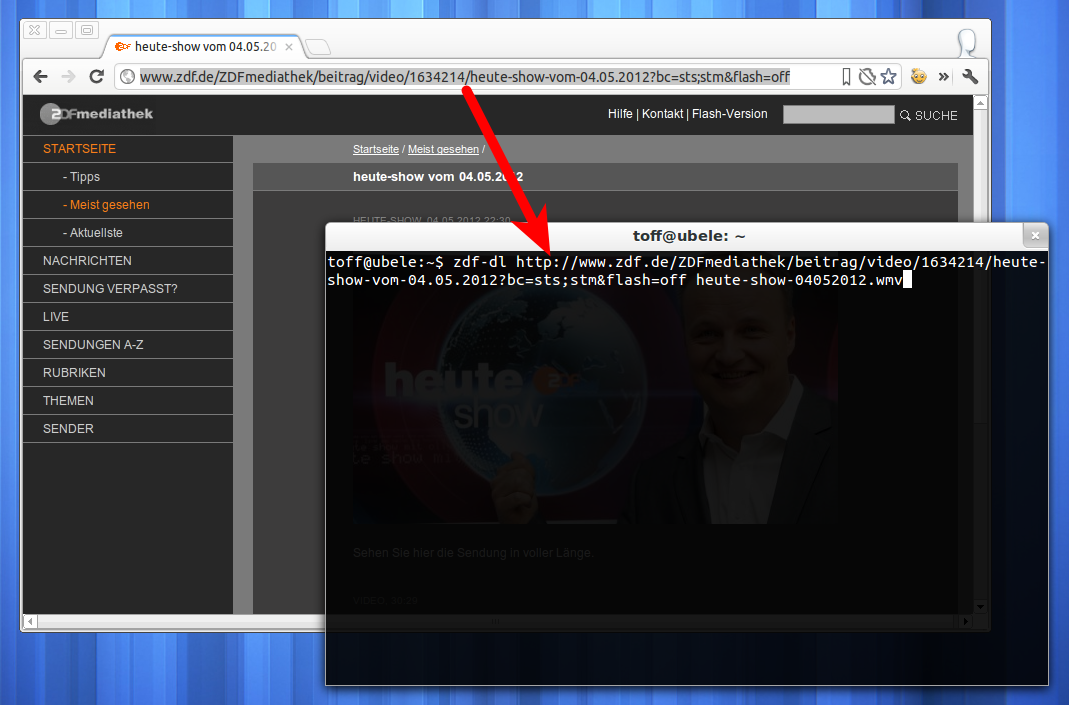
$ zdf-dl "http://www.zdf.de/ZDFmediathek/beitrag/video/1634214/heute-show-vom-04.05.2012?bc=sts;stm&flash=off"Achtet aber bitte drauf URLs zur HTML-Version der ZDF-Mediathek zu nutzen. Aus der Flash-Variante lässt sich die URL zum Stream nur schwer generieren, daher funktioniert zdf-dl auch nur mit Links, die eben ein „flash=off“ enthalten. Das Skript generiert aus der URL einen Dateinamen, wer lieber selber Namen vergibt, der packt diesen einfach noch ans Ende des Kommandos.
$ zdf-dl "http://www.zdf.de/ZDFmediathek/beitrag/video/1634214/heute-show-vom-04.05.2012?bc=sts;stm&flash=off" heute-show.wmaDas Beispiel ist aufgrund der Depublizierung ja nur ein paar Tage gültig, aber ich denke Ihr wisst wohin der Zug geht. Die Anführungszeichen rund um die URL sind leider nötig, da in den URLs der Mediathek öfters mal ein Ampersand „&“ steckt, ohne die Anführungszeichnen interpretiert die Shell die Eingabe leider als foobar & und übergeht den Rest der Eingabe.
HINWEIS: Kleiner Tipp am Rande: Mit youtube-dl gibt es ein Kommandozeilen-Tool mit dem sich sehr bequem YouTube-Videos auf die Festplatte laden lassen. Das Programm kann aber deutlich mehr, als es der Namen vermuten lässt. Youtube-dl lädt auch Videos von anderen Video-Plattformen wie Vimeo oder MyVideo herunter. Zudem unterstützt das Programm auch diverse Mediatheken wie die der öffentlich-rechtlichen Sender ARD und ZDF. Allgemeine Flash-Videos diverse Videohoster holen Sie sich am besten direkt aus dem Zwischenspeicher auf die Festplatte: Flash Video Download Linux.










Prinzipiell eine nette Idee. Praktisch kann man aber zwei Dinge schöner machen:
– Die per rtmp ausgelieferte Datei hat eine bessere Qualität als die .wmv-Datei
– Die ZDFmediathek hat extra eine XML-basierte API ( http://www.zdf.de/ZDFmediathek/xmlservice/web/beitragsDetails?id=$1 ). Da braucht man dann nicht zu Screenscrapen sondern kann ein wohldefiniertes Format verwenden.
Etwa so: http://paste.ubuntuusers.de/408042/
Hi Funatiker, die Mediathek hat eine API? Klasse, wusste ich nicht. Ich baue das entsprechend um.
Grüße
Christoph
Hallo Christoph
Ich verfolge schon seit einer längeren Zeit deinen Blog und es gefält mir immer wieder die neuen Aspekte, die ich bei dir kennen lerne.
So auch wieder heute… mit diesen kurzen Zeilen Code.
Zur Verbesserung, die mir einfallen.
1. Mehrfach auswahl bei der Qualität und Format, bei einem Stream mit 2 Qualitäten, übergibt das Skript zwei URL’s, die zweite verursacht einen Fehler
Mein Vorschlag wäre dies mit einem Qualitäts-Schalter zurealisieren.
2. Durch die Ermitlung der ID könnte man auch die Flash-URL nehmen und ein ?flash=no dran hängen. Damit wäre es egal welche URL man verwendet.
Leider muss man dann den Namen wo anders herholen.
Jonas
Edit: Da war wohl jemand schneller. Die API kannte ich noch nicht.
Super und Danke!
Sehr interessant geschrieben – vielen Dank.
Ich will jetzt auch kein Spielverderber sein, gibts aber doch schon als Software (sogar für Linux):
http://www.heise.de/download/mediathekview.html
Trotzdem sehr schön und informativ geschrieben!
Bist kein Spielverderber 😉 MediathekView kenne ich, aber es gibt eineb Unterschied zwischen einem dicken Java-Programm und einem kleinen Skript 😉
Grüße
Christoph
Geht auch ohne alles:
1. Gewünschten Beirtrag in ZDF Mediathek in der html-Version laden
2. Die Adresszeile mit ergänzen durch „&ipad=true“ (ohne Anführungsstriche)
3. Seite damit neu laden
4. Dort wo „Abspielen“ steht, rechts klicken -> Speichern unter und der Film ist auf der Platte.
Ebenfalls Danke!
Versuche jetzt den gesamten Sonntag schon, ein Video der MDR Mediathek herunter zu laden. Habe MediathekView ausprobiert, aber das hängt sich mit einer Fehlermeldung auf. Die neueste BETA Version stürzt schon vor dem herunterladen ab. Habe ein paar Browserplugins und Kommandozeilen Tools probiert, aber komme nicht weiter. Hat irgend jemand eine Idee?
Hier der Link: http://www.mdr.de/mediathek/fernsehen/a-z/video54350_zc-ea9f5e14_zs-dea15b49.html
Die MDRmediathek bietet ebenfalls eine XML-basierte API an. Dazu muss man die Video-ID kennen. Das ist in diesem Fall „video54350”. Die Adresse zur API lautet dann:
http://www.mdr.de/mediathek/fernsehen/a-z/video54350-avCustom.xml
Mit etwas grep-Magic bekommt man so einen Stapel voll URLs in unterschiedlicher Qualität:
wget -q -O- http://www.mdr.de/mediathek/fernsehen/a-z/video54350-avCustom.xml | grep progressiveDownloadUrl | cut -d\> -f2 | cut -d\< -f1
Wow, danke für die schnelle Antwort! Hat mir wirklich geholfen. Mein Vater wollte den Beitrag ganz dringend für immer auf Festplatte bannen. 😉 Mitschnitt vom MDR kostet ja um die 40€, das ist für 25min ganz schön happig!
Ich hab mir jetzt zwar schon den besten Stream herausgesucht, aber rein interessehalber: gibt es eine Möglichkeit automatisch den besten Stream auszuwählen? Also, kann man wget anweisen, den Stream mit der besten Qualität zu laden bzw. die größte Datei in dem Fall?! Hab mir eben mal die Hilfedatei angeschaut und nichts dergleichen gefunden. Vielleicht mit grep? Dazu müsste man dann aber irgendwie die Dateigröße aller Links ermitteln können… ?!
Das Teure am Mittschnittdienst der Fernsehsender ist, das tatsächlich händisch Mitschnitte kopiert werden müssen. Genau deswegen gibt es ja die Mediatheken und ihre (leider nicht dokumentierten) APIs.
Die Download-Server geben an, wie groß die Datei ist. Theoretisch (als rein technisch gesehen) könnte wget eine Liste von URLs durchprobieren und die größte Datei komplett laden. Praktisch ist so eine Funktion nicht in wget implementiert.
Wenn du einen Blick auf die genannte XML-Datei wirfst, siehst du, dass die Kindknoten von avDocument → assets, also die asset-Tags, ihrerseits ein Tag fileSize und ein Tag progressiveDownloadUrl enthalten. Das erstgenannte gibt die Dateigröße in Byte an, das zweite den Downloadlink. Es wäre möglich die XML-Datei entsprechend zu behandeln.
Im vorliegenden Fall ist die größte Datei jedoch die zweite. Ein „sed -n 2p“ nach dem grep-Befehl würde nur diese Zeile ausgeben. Etwa:
wget -q -O- http://www.mdr.de/mediathek/fernsehen/a-z/video54350-avCustom.xml | grep progressiveDownloadUrl | sed -n 2p | cut -d\> -f2 | cut -d\< -f1
Im allgemeinen Fall ist diese Methode jedoch nicht immer verlässlich, weil die Reihenfolge der Links zu den unterschiedlichen Formaten ja nicht unbedingt fest sein muss. Bei Stichproben hat sich diese Heuristik jedoch als zutreffend erwiesen.
Hmm, wenn man jetzt das Script automatisch die Größte Datei auswhählen lassen könnte (abhängig von der Dateigröße, nicht von der Reihenfolge in der XML), könnte man das ganze als MDR-Script verpacken! 😉 Ich muss mich wirklich mal mit shell Befehlen/programmieren im Allgemeinen mehr auseinandersetzen. Komm mir immer so dumm vor fragen zu müssen. 😉
Jedenfalls Danke für Deine Hilfe!
Wie gesagt. Bislang ist das beste Format immer das zweite in der Liste. Aber das ist nur eine Heuristik. Für den Anfang würde das eigentlich reichen.
Vielen Dank! Endlich kann die Kiste ausbleiben. 🙂
Also ich bin ein Anfänger und finde es tausend mal praktischer einfach via Wine 1.4.1 den Adobe Flash Player für Windows zu installieren, danach das kostenlose Programm StreamTransport…einfach alles viel hübscher und sooooo einfach 🙂 ! Danke nochmal an das WINE-Team, ihr seid klasse 😀 ich freue mich schon auf Wine 1.6 😉 !
Klasse Script und ob es da andere Programme gibt die vielleicht besser sind ist eigentlich egal, ein paar Zeilen Bash Code sind mir lieber. Ein großes Dankeschön an den Christoph funktioniert super das Script.
Hallo,
habe gerade keine Linux Maschine zur Hand, die 7-Tage-Beschränkung lässt mich panisch werden, dass ich verpasse Lund III Folge 5 zu verpassen.
Der Link zeigt nur auf ein FSK-Beschränkungs-Video…. ich nehme an, wenn ich das script nutze, dann hab ich nur die FSK Vorschau, richtig ?
http://www.zdf.de/ZDFmediathek/beitrag/video/1851822/Kommissarin-Lund-III—Folge-5?bc=sts;suc&flash=off
/To
Hallo, To!
Du hast in der Tat Recht: Auch die API liefert vor 20 Uhr nur den FSK-12-Warnhinweis. Wenn du jedoch nach 20 Uhr die XML-Ausgabe der API unter:
http://www.zdf.de/ZDFmediathek/xmlservice/web/beitragsDetails?id=1851822
speicherst, kannst du zu jeder Zeit aus dieser die Links entnehmen und die Datei sichern.
Danke für die Info, wusste nicht, dass sich das dynamisch ändert.
Das Script funktioniert nicht mehr.
Hi Peter, ich schau mir das die Tage mal an. Grüße, Christoph.
Die Mediathek unterstützt nun immerhin html5.
http://hstreaming.zdf.de/zdf/veryhigh/XX/XX/XX.mov
Lässt sich aber nicht herunterladen. Muss man wohl irgentwie dumpen.
Dennoch die Quallität zu wünschen übrig. „veryhigh“ „HQ“ ist unverschämt 😛
Chris, kurzer Hinweis:
Die ZDF-Filme liegen nicht mehr im .asx-Format, sondern im .mov-Format vor. Ersetzt man das grep asx (Zeile 18) durch grep mov und führt das Skript aus, so funzt es insofern, als dass mplayer startet und den Film anzeigt. Das Skript muss noch so angepasst werden, dass mplayer nicht startet, sondern nur lädt.
Eventuell kann in Zeile 33 das „.wmv“ ebenfalls durch „.mov“ ersetzt werden, da der curl-Befehl (Zeile 18) ebenfalls eine .mov auswirft.
Was ebenfalls funzt, ist http://wiki.ubuntuusers.de/Streams_speichern#2-Moeglichkeit-2. Den Link mit dem http://rodl.zdf.de… kann man dann per wget runterladen (Format ist dann .3gp). Dieses Verfahren kann eventuell das No-Flash-only-Seite („Check if No Flash Mediathek is used“) beheben.
Liebe Grüße,
Flo
Was habt ihr alle mit dieser NoFlash-Seite? IMHO sind die dort angegebenen Streams zu nichts mehr zu gebrauchen. Über die XML-API bekommt man inzwischen sogar ein webm-Video über http. Ganz ohne Playlist o.Ä.
Ungefähr so (ungetestet):
url_id=$(echo „$1“ | grep -o ‚[0-9][0-9]*‘ | head -n1)
url_stream=$(curl -s „http://www.zdf.de/ZDFmediathek/xmlservice/web/beitragsDetails?id=${url_id}“ | grep .webm | tail -n1 | grep -o ‚http://[^<]*'
Hi Chris, wie sieht es denn mittlerweile aus? Es wäre wirklich toll, wenn du das Tool auf den neuesten Stand bringen könntest – ich bin gerade neu in der Linuxwelt und kann mir sowas leider (noch!) nicht allein basteln, und für meinen Raspberry Pi, den ich als Medienserver eingerichtet habe, wäre das wirklich genau das Richtige 😉
Hallo Christoph.
Bin der Anleitung gefolgt, bekomme die Meldung
Lade *.wmv herunter, bitte haben Sie etwas Geduld…
aber dann fehlt das Video. Dauert auch nur 3 Sek., während tatort-dl.sh schon mal 5 Min. dauern kann. Was mach ich falsch?
Danke.
Hallo, ich habe das Skript modifiziert, so funktioniert es tadellos:
mov_id=$(echo "${url_noflash}" | grep -oP "(?<=http://www.zdf.de/ZDFmediathek/beitrag/video/)[^/]+") echo "Film id: ${mov_id}" url_xmlfile=$(echo "http://www.zdf.de/ZDFmediathek/xmlservice/web/beitragsDetails?id=${mov_id}") echo "Pfad xml-Datei: ${url_xmlfile}" xmlfile=$(curl -s ${url_xmlfile}) # Extract from xml-file the elements "formitaet", then search for "veryhigh", then for filename pattern url_stream=$(echo ${xmlfile} | xmlstarlet sel -t -m '//formitaet' -v . -n | grep -n1 'veryhigh' | grep -o 'http://rodl.zdf.de/none/zdf[^"]*.m p4') # Get stream and save it to disk echo "Lade ${url_stream} herunter, bitte haben Sie etwas Geduld..." wget -c ${url_stream}Spät, aber besser als nie! Hab deine Änderungen in zdf-dl integriert, jetzt funktioniert das Skript auch wieder. Siehe https://github.com/linuxundich/zdf-dl
Hallo Christoph,
danke für den Artikel zum Thema Streams herunterladen. Eine andere, etwas unkonventionelle Art habe ich in meinem Artikel zum Thema Streams von Streaming Servern herunterladen beschrieben. Vielleicht ist das ja was für Deine Leser. 🙂
Videos von illegalen Webseiten mit JDownloader herunterzuladen ist nicht „unkonventionell“ sondern gewöhnlich. Es ist sogar derart gewöhnlich, dass davon auszugehen ist, dass dein Artikel und dein Kommentar nur zwecks Suchmaschinenspam platziert wurden.
Unkonventionell wäre es, Videos aus legalen Mediatheken aufzunehmen, indem man die Techniken auseinander nimmt und sich selbst überlegt, wie man das Video wegspeichert.